









Cấu trúc dữ liệu là cách tổ chức và lưu trữ dữ liệu để sử dụng một cách hiệu quả nhất. Đối với mỗi doanh nghiệp, việc có một cấu trúc dữ liệu chặt chẽ là vô cùng quan trọng. Mục đích của cấu trúc dữ liệu là giúp quản lý thông tin một cách khoa học, dễ dàng và hiệu quả. Khi dữ liệu được tổ chức một cách cẩn thận, nó không chỉ giúp đảm bảo quá trình làm việc trơn tru mà còn tăng tính chuyên nghiệp và tinh tế cho doanh nghiệp.
Vậy cấu trúc dữ liệu có những loại nào thông dụng? Đâu sẽ là loại cấu trúc dữ liệu phù hợp với doanh nghiệp của bạn? Hãy cùng tìm hiểu thêm trong phần dưới đây.
Cấu trúc dữ liệu là gì?
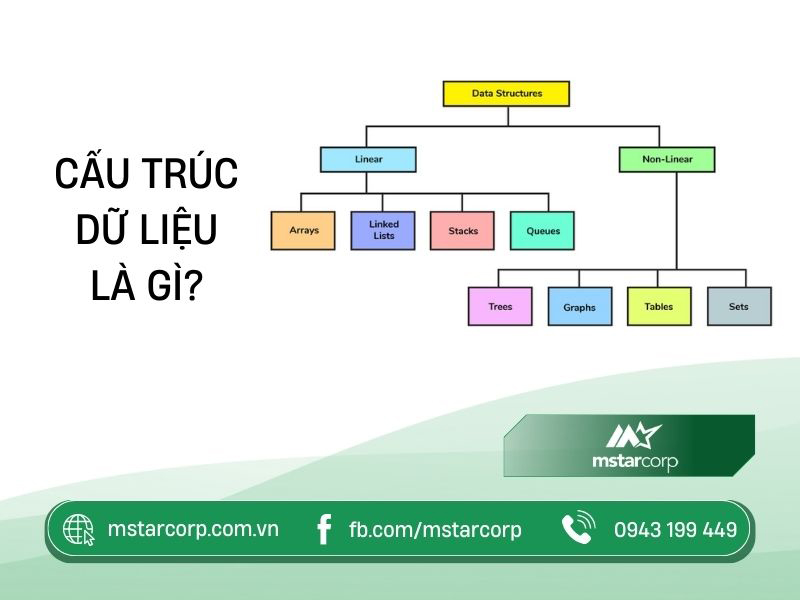
Cấu trúc dữ liệu (Data Structure) là cách tổ chức và lưu trữ dữ liệu theo hệ thống và thứ tự nhất định để tối ưu hóa việc sử dụng tài nguyên. Có nhiều phương pháp khác nhau để lưu trữ dữ liệu trong bộ nhớ, nhưng mảng trong ngôn ngữ C thường được ưa chuộng nhất trong thực tế.
Cấu trúc dữ liệu là một bộ sưu tập các thuật toán và nguyên tắc mà chúng ta có thể áp dụng để tổ chức và sử dụng dữ liệu trong bộ nhớ. Nó không ảnh hưởng bởi ngôn ngữ lập trình cụ thể. Các thuật toán này thường được thể hiện dưới dạng các kiểu dữ liệu trừu tượng, tức là một tập hợp các quy tắc mô tả cách dữ liệu được tổ chức và hoạt động.
Các hoạt động phổ biến thể hiện trên cấu trúc dữ liệu là:
- Tìm kiếm: Tìm kiếm tất cả các phần tử
- Sắp xếp: Sắp xếp các phần tử theo thứ tự tăng/giảm dần
- Chèn: Chèn thêm các phần tử mới
- Cập nhật: Thay thế hoặc cập nhật một phần tử nào đó trong cấu trúc dữ liệu bằng một phần tử khác.
- Xóa: Các lập trình viên có thể sử dụng lệnh xóa để loại bỏ phần tử.
Mục đích của cấu trúc dữ liệu là gì?

- Lưu trữ dữ liệu: Cấu trúc dữ liệu được sử dụng để duy trì dữ liệu một cách hiệu quả, ví dụ như việc xác định tập hợp các thuộc tính và cấu trúc tương ứng được áp dụng để lưu trữ các bản ghi trong hệ thống quản lý cơ sở dữ liệu.
- Quản lý tài nguyên và dịch vụ: Các tài nguyên và dịch vụ của hệ điều hành (OS) cốt lõi được quản lý thông qua việc sử dụng các cấu trúc dữ liệu như danh sách liên kết để cấp phát bộ nhớ, quản lý thư mục tệp và cây cấu trúc.
- Trao đổi dữ liệu: Cấu trúc dữ liệu định nghĩa cách tổ chức thông tin được chia sẻ giữa các ứng dụng, chẳng hạn như các gói TCP/IP.
- Đặt hàng và phân loại: Ví dụ, cây tìm kiếm nhị phân, còn được gọi là cây nhị phân được sắp xếp hoặc sắp xếp, cung cấp các phương pháp hiệu quả để sắp xếp đối tượng, chẳng hạn như chuỗi ký tự được sử dụng làm thẻ. Điều này cho phép lập trình viên quản lý các mục được sắp xếp theo mức độ ưu tiên cụ thể.
- Lập chỉ mục: Cấu trúc dữ liệu hỗ trợ quá trình lập chỉ mục. Ngay cả các cấu trúc dữ liệu như cây B có thể được dùng để tạo chỉ mục cho các đối tượng. Ví dụ như các đối tượng được lưu trữ trong cơ sở dữ liệu.
- Tìm kiếm: Các chỉ mục được tạo ra bằng cách sử dụng cây tìm kiếm nhị phân, cây B hoặc bảng băm có khả năng tăng tốc tìm kiếm một mục cụ thể.
- Khả năng mở rộng: Ứng dụng dữ liệu lớn thường sử dụng cấu trúc dữ liệu để phân phối và quản lý lưu trữ dữ liệu trên nhiều vị trí lưu trữ. Điều đó đảm bảo khả năng mở rộng và hiệu suất.
Cấu trúc dữ liệu ảnh hưởng như thế nào đến doanh nghiệp?
Cấu trúc dữ liệu là một trong những yếu tố quan trọng nhất đối với các doanh nghiệp trong thời đại số hóa ngày nay. Đối với mỗi doanh nghiệp, lượng dữ liệu mà họ phải xử lý ngày càng tăng lên một cách đáng kể. Từ dữ liệu về khách hàng, giao dịch, sản phẩm đến dữ liệu nội bộ của doanh nghiệp,… Đồng thời, các ứng dụng và hệ thống thông tin của doanh nghiệp cũng trở nên phức tạp hơn để đáp ứng nhu cầu ngày càng cao của thị trường và khách hàng.
Trong môi trường kinh doanh ngày nay, tốc độ truy cập và xử lý dữ liệu trở thành yếu tố quyết định cho sự thành công của một doanh nghiệp. Điều này đặt ra một thách thức lớn cho việc quản lý và sử dụng dữ liệu một cách hiệu quả. Điều quan trọng là phải có một cơ sở dữ liệu được tổ chức và quản lý một cách hợp lý để đảm bảo rằng dữ liệu có thể được truy cập nhanh chóng và hiệu quả, từ đó giúp doanh nghiệp ra quyết định chính xác và kịp thời.
Do đó, cấu trúc dữ liệu chính là công cụ giúp giải quyết vấn đề này. Bằng cách tổ chức dữ liệu một cách logic và có hệ thống, cấu trúc dữ liệu giúp tối ưu hóa quá trình truy cập, thêm, sửa, và xóa dữ liệu. Dưới đây là những yếu tố giúp doanh nghiệp của bạn chọn lựa được cấu trúc dữ liệu phù hợp và hiệu quả:
Phân loại dữ liệu
Trước hết, cần xem xét loại dữ liệu mà bạn đang cần lưu trữ và xử lý. Các cấu trúc dữ liệu khác nhau có thể phù hợp hơn với các loại dữ liệu cụ thể như số liệu, dữ liệu phân loại, hoặc dữ liệu phân cấp.
Các hoạt động mong muốn
Tiếp theo, bạn cần xác định các hoạt động chính mà bạn muốn thực hiện trên dữ liệu. Mỗi cấu trúc dữ liệu cung cấp các cấu hình hiệu suất khác nhau cho các hoạt động cụ thể như chèn, xóa, tìm kiếm hoặc cập nhật. Hãy chọn cấu trúc dữ liệu hỗ trợ các hoạt động mong muốn của bạn một cách hiệu quả về thời gian và không gian.
Các yêu cầu thực hiện
Đánh giá nhu cầu hiệu suất của ứng dụng của bạn. Nếu tốc độ là yếu tố quan trọng, hãy chọn cấu trúc dữ liệu có thời gian truy cập nhanh. Nếu việc sử dụng bộ nhớ là hạn chế quan trọng hơn, hãy xem xét các cấu trúc dữ liệu có chi phí bộ nhớ tối thiểu.
Khả năng mở rộng
Nếu ứng dụng của bạn dự kiến sẽ xử lý các tập dữ liệu ngày càng lớn, hãy chọn cấu trúc dữ liệu có thể mở rộng mà không làm giảm hiệu suất đáng kể. Cấu trúc dữ liệu có khả năng mở rộng cho phép phần mềm của bạn duy trì hiệu quả ngay cả khi yêu cầu lưu trữ dữ liệu của nó tăng lên theo thời gian.
Tính linh hoạt
Khi lựa chọn cấu trúc dữ liệu, cần xem xét tính linh hoạt và khả năng mở rộng của nó. Một cấu trúc dữ liệu linh hoạt có thể thích ứng với các yêu cầu mới và thay đổi trong tương lai mà không cần phải thay đổi hoặc tái thiết kế toàn bộ hệ thống.
Các đặc tính của Data structure là gì?

Cấu trúc dữ liệu thường được phân loại dựa trên các đặc tính của chúng. Dưới đây là ba đặc tính được sử dụng để phân loại cấu trúc dữ liệu:
- Tính tuyến tính hoặc phi tuyến tính: Đặc tính này mô tả liệu các mục dữ liệu được sắp xếp theo thứ tự hay không. Cấu trúc dữ liệu tuyến tính là một cấu trúc trong đó các phần tử được tổ chức theo một trình tự cụ thể, trong khi cấu trúc phi tuyến tính không có trình tự cố định cho các phần tử.
- Tính đồng nhất hoặc không đồng nhất: Đặc tính này mô tả liệu tất cả các mục dữ liệu trong một kho lưu trữ nhất định có cùng loại hay không. Trong cấu trúc dữ liệu đồng nhất, tất cả các phần tử có cùng kiểu dữ liệu và thuộc tính, trong khi cấu trúc không đồng nhất có thể chứa các loại dữ liệu và thuộc tính khác nhau.
- Tính tĩnh hoặc động: Đặc tính này mô tả cách các cấu trúc dữ liệu được biên dịch. Cấu trúc dữ liệu tĩnh có kích thước, cấu trúc và vị trí bộ nhớ cố định tại thời điểm biên dịch, không thay đổi trong quá trình thực thi. Trái lại, cấu trúc dữ liệu động có kích thước, cấu trúc và vị trí bộ nhớ có thể thay đổi theo thời gian và tùy thuộc vào việc sử dụng trong quá trình thực thi.
8 kiểu cấu trúc dữ liệu thông dụng
Có đa dạng loại cấu trúc dữ liệu, mỗi loại đều có những ưu điểm và nhược điểm riêng. Lựa chọn sử dụng cấu trúc dữ liệu thường phụ thuộc vào loại thuật toán hoặc ứng dụng cụ mà người dùng muốn triển khai. Dưới đây là 8 dạng cấu trúc dữ liệu phổ biến:
Arrays
Arrays là một cấu trúc dữ liệu lưu trữ một chuỗi các phần tử có cùng kiểu dữ liệu trong một vùng nhớ liên tục.
Phân loại cụ thể:
- Theo kích thước cố định (mảng tĩnh).
- Theo kích thước có thể thay đổi (mảng động).
Ứng dụng: Mảng thường được sử dụng để lưu trữ dữ liệu có thứ tự, như danh sách các phần tử hoặc dữ liệu ma trận. Nó cũng được sử dụng cho việc triển khai các cấu trúc dữ liệu khác như stack và queue.
Ưu điểm:
- Truy cập nhanh đến phần tử theo chỉ mục.
- Dễ dàng sử dụng và triển khai.
Nhược điểm:
- Kích thước cố định cho mảng tĩnh.
- Khả năng chèn và xóa phần tử không hiệu quả đối với mảng tĩnh.
Linked Lists
Linked lists là một cấu trúc dữ liệu mà các phần tử được kết nối với nhau thông qua các liên kết.
Phân loại cụ thể:
- Singly linked list ( danh sách liên kết đơn)
- Doubly linked list (danh sách liên kết đôi)
- Circular linked list (danh sách liên kết vòng)
Ứng dụng:
- Áp dụng cho quản lý bảng ký hiệu trong quá trình thiết kế compiler.
- Áp dụng để chuyển đổi giữa các chương trình bằng cách sử dụng phím tắt Alt + Tab (được triển khai bằng Danh sách Liên kết Vòng).
Ưu điểm: Khả năng linh hoạt trong thêm/xóa phần tử, không giới hạn về kích thước của danh sách.
Nhược điểm: Truy cập ngẫu nhiên chậm hơn so với mảng, do phải duyệt qua các liên kết từ đầu.
Hash function
Hash function là một hàm toán học chuyển đổi dữ liệu thành một giá trị số nguyên có kích thước cố định, gọi là hash code hoặc hash value.
Phân loại cụ thể:
- Hash function đơn giản (phép chia).
- Hash function phức tạp (SHA-256).
Ứng dụng:
- Sử dụng trong việc tạo ra các cấu trúc dữ liệu như bảng băm (hash table)
- Sử dụng trong bảo mật để mã hóa dữ liệu.
Ưu điểm: Tốc độ truy cập nhanh, giúp giảm thời gian tìm kiếm dữ liệu trong các cấu trúc dữ liệu lớn.
Nhược điểm: Có thể xảy ra hiện tượng xung đột hash khi hai dữ liệu khác nhau được ánh xạ vào cùng một hash value.
Stacks
Stack là một cấu trúc dữ liệu dạng ngăn xếp, theo cơ chế “Last In, First Out” (LIFO), nghĩa là phần tử được thêm vào cuối cùng sẽ được lấy ra trước tiên.
Phân loại cụ thể:
- Stack dùng mảng.
- Stack dùng danh sách liên kết.
Ứng dụng:
- Sử dụng trong việc quản lý hàm gọi (call stack) trong lập trình.
- Sử dụng trong các thuật toán như duyệt cây theo chiều sâu (DFS).
Ưu điểm: Cài đặt đơn giản, thao tác thêm và loại bỏ phần tử hiệu quả.
Nhược điểm: Không thể truy cập hoặc thay đổi các phần tử không phải ở đỉnh của ngăn xếp.
Hash table
Hash table là một cấu trúc dữ liệu lưu trữ dữ liệu dưới dạng cặp khóa – giá trị, trong đó giá trị được truy cập thông qua một hàm hash.
Phân loại cụ thể: Có nhiều phương pháp triển khai hash table như:
- Separate chaining.
- Open addressing.
Ứng dụng: Thường được sử dụng để lưu trữ dữ liệu có thứ tự và cung cấp việc truy cập nhanh tới dữ liệu dựa trên khóa.
Ưu điểm: Tìm kiếm, thêm và xóa dữ liệu có thể thực hiện trong thời gian gần như hằng số trong trường hợp tốt nhất.
Nhược điểm: Đòi hỏi việc quản lý xung đột hash và chi phí bộ nhớ cao hơn so với một số cấu trúc dữ liệu khác.
Queue
Queue là một cấu trúc dữ liệu dạng hàng đợi, theo cơ chế “First In, First Out” (FIFO), nghĩa là phần tử được thêm vào trước tiên sẽ được lấy ra đầu tiên.
Phân loại cụ thể: Có nhiều loại Queue như:
- Hàng đợi dùng mảng
- Hàng đợi dùng danh sách liên kết.
Ứng dụng:
- Được áp dụng để điều phối luồng trong đa luồng.
- Được dùng để triển khai các hệ thống hàng đợi.
Ưu điểm: Thực hiện thêm và xóa phần tử ở hai đầu của hàng đợi một cách hiệu quả.
Nhược điểm: Không thể truy cập hoặc thay đổi các phần tử không phải ở đầu của hàng đợi.
Heaps
Heaps là một cấu trúc dữ liệu cây nhị phân đặc biệt, thường được sử dụng để triển khai hàng đợi ưu tiên, trong đó phần tử ưu tiên cao nhất luôn ở đỉnh cây.
Phân loại cụ thể: Có hai loại heap phổ biến:
- Max heap.
- Min heap (Tùy thuộc vào thứ tự sắp xếp của các phần tử).
Ứng dụng:
- Được áp dụng trong thuật toán heapsort.
- Được dùng để triển khai hàng đợi ưu tiên.
- Các chức năng của hàng đợi có thể được cài đặt bằng cách sử dụng heap với độ phức tạp là O(log n).
- Sử dụng để tìm giá trị lớn (nhỏ) thứ k trong một mảng đã cho.
Ưu điểm: Đảm bảo rằng phần tử ưu tiên luôn có thể được truy cập và xóa một cách hiệu quả.
Nhược điểm: Thao tác thêm phần tử mới có thể đòi hỏi thời gian để duy trì tính chất của heap.
Tree
Tree là một cấu trúc dữ liệu phân cấp có thể được sắp xếp dưới dạng các nút liên kết với nhau theo mối quan hệ cha – con.
Phân loại cụ thể:
- Cây nhị phân
- Cây tìm kiếm nhị phân
- Cây AVL và cây đỏ – đen.
Ứng dụng: Trees được sử dụng trong rất nhiều lĩnh vực như: Cơ sở dữ liệu, hệ thống tệp, và thuật toán tìm kiếm và sắp xếp.
Ưu điểm: Cung cấp cách tổ chức dữ liệu hiệu quả cho các tình huống phức tạp và cho phép thực hiện các thao tác tìm kiếm và thêm/xóa một cách hiệu quả.
Nhược điểm: Thao tác cập nhật dữ liệu có thể đòi hỏi nhiều thời gian và tài nguyên so với một số cấu trúc dữ liệu khác.
Graph
Graph là một cấu trúc dữ liệu biểu diễn các mối quan hệ giữa các đối tượng, được biểu diễn dưới dạng tập hợp các đỉnh (nodes) và các cạnh (edges) kết nối các đỉnh với nhau.
Phân loại cụ thể: Có nhiều loại đồ thị như:
- Đồ thị vô hướng.
- Đồ thị có hướng.
- Đồ thị có trọng số và đồ thị có hướng với trọng số.
Ứng dụng: Đồ thị được sử dụng trong nhiều lĩnh vực như
- Mạng lưới mạng xã hội.
- Tối ưu hóa đường đi, hệ thống giao thông.
- Phân tích mạng xã hội và tìm kiếm trong dữ liệu.
Ưu điểm: Biểu diễn mối quan hệ phức tạp giữa các đối tượng một cách rõ ràng và linh hoạt, cho phép giải quyết các vấn đề phức tạp một cách hiệu quả.
Nhược điểm: Thao tác trên đồ thị có thể phức tạp và đòi hỏi nhiều tài nguyên tính toán so với một số cấu trúc dữ liệu khác.
Các lưu ý khi sử dụng cấu trúc dữ liệu
Dưới đây là các yếu tố quan trọng khi lựa chọn và quản lý cấu trúc dữ liệu:
- Lựa chọn cấu trúc dữ liệu phù hợp: Không có cấu trúc nào phù hợp cho mọi vấn đề. Vì vậy, bạn cần chọn loại cấu trúc dữ liệu phù hợp cho từng vấn đề cụ thể.
- Đảm bảo tính an toàn và bảo mật của dữ liệu: Bảo vệ dữ liệu khỏi các cuộc tấn công từ bên ngoài và bảo vệ dữ liệu khỏi các lỗi trong chương trình là một ưu tiên quan trọng.
- Tối ưu hóa cấu trúc dữ liệu: Tìm kiếm cấu trúc phù hợp nhất để đáp ứng các yêu cầu của chương trình và đảm bảo hiệu năng và tốc độ thực thi tối đa.
- Kiểm tra lỗi và xử lý ngoại lệ: Kiểm tra lỗi và xử lý ngoại lệ giúp đảm bảo tính ổn định và an toàn của chương trình, bằng cách xử lý các vấn đề như lỗi tràn bộ nhớ và lỗi truy xuất.
- Hiểu rõ các thao tác và cách sử dụng: Hiểu rõ các thao tác và cách sử dụng của các cấu trúc dữ liệu sẽ giúp bạn sử dụng chúng một cách hiệu quả và tránh các lỗi có thể phát sinh.
- Bảo trì và cập nhật: Các cấu trúc dữ liệu có thể cần được bảo trì và cập nhật để đáp ứng các yêu cầu mới và giảm thiểu các lỗi và vấn đề.
Khác biệt giữa cấu trúc dữ liệu và kiểu dữ liệu
| Tính chất | Kiểu dữ liệu (Data Type) | Cấu trúc dữ liệu (Data Structure) |
| Mô tả | Khái niệm trừu tượng dùng để miêu tả loại dữ liệu của một giá trị. | Đó là một tập hợp các loại dữ liệu khác nhau. Toàn bộ dữ liệu đó có thể được đại diện bằng một đối tượng và được sử dụng trong toàn bộ chương trình. |
| Loại dữ liệu | Đó là một dạng của biến mà có thể được gán giá trị. Nó xác định rằng biến cụ thể sẽ chứa các giá trị thuộc về một kiểu dữ liệu nhất định. | Chứa nhiều loại dữ liệu trong một đối tượng. |
| Khả năng lưu | Có thể lưu trữ giá trị nhưng không lưu trữ dữ liệu. | Thông tin và giá trị tương ứng được lưu trữ trong bộ nhớ chính của máy tính. |
| Triển khai | Triển khai trừu tượng (abstract implementation) | Triển khai cụ thể (concrete implementation) |
| Độ phức tạp của thuật toán | Thuật toán không có độ phức tạp. | Sự phức tạp của thuật toán đóng một vai trò quan trọng. |
| Lưu trữ giá trị | Không lưu trữ giá trị, chỉ biểu diễn cho kiểu dữ liệu. | – |
| Ví dụ | Ví dụ: int, float, double, … | Ví dụ: stack, queue, tree, … |
Tại sao cấu trúc quản lý dữ liệu lại quan trọng với một doanh nghiệp số?
Cấu trúc quản lý dữ liệu quan trọng với doanh nghiệp bởi những ưu điểm vượt trội sau:
- Xử lý lượng dữ liệu lớn và phức tạp: Cấu trúc quản lý dữ liệu 2 tốc độ giúp doanh nghiệp đối đầu với lượng dữ liệu ngày càng lớn và phức tạp từ nhiều nguồn khác nhau.
- Hỗ trợ các kỹ thuật kinh doanh mới: Cấu trúc này cho phép triển khai các kỹ thuật kinh doanh mới như đặt giá cá nhân cho khách hàng dựa trên lợi nhuận thời gian thực hoặc tự động hóa các quyết định tín dụng.
- Tối ưu hóa chiến lược kinh doanh: Cấu trúc này giúp doanh nghiệp tối ưu hóa chiến lược kinh doanh bằng cách tận dụng dữ liệu để hiểu rõ hơn về khách hàng, thị trường và cạnh tranh.
- Tăng cường phát hiện và phòng ngừa lừa đảo: Cấu trúc này giúp tăng cường phát hiện và phòng ngừa lừa đảo thông qua phân tích dữ liệu và thống kê thời gian thực.
- Tích hợp linh hoạt và hiệu quả: Cấu trúc này cho phép tích hợp các giải pháp mới một cách linh hoạt với các hệ thống truyền thống và tạo ra một cơ sở dữ liệu linh hoạt và hiệu quả.
Ví dụ: Một ngân hàng lớn ở Scandinavia đã bắt đầu hành trình quản lý dữ liệu của họ để tối ưu hóa các hoạt động kinh doanh chủ chốt như tăng cường phát hiện lừa đảo và phân bố chi nhánh. Thay vì rũ bỏ hệ thống công nghệ thông tin hiện tại, họ tích hợp một giải pháp Hadoop để xử lý và phân phối dữ liệu lớn và không cấu trúc. Kết quả là họ đã đạt được mục tiêu kinh tế chủ chốt với một đầu tư nhỏ lẻ vào công nghệ, đồng thời tạo ra giá trị thực sự cho doanh nghiệp.
Thông qua đây, ta cũng có thể thấy được việc áp dụng cấu trúc quản lý dữ liệu là điều cực kỳ cần thiết. Bằng cách tích hợp công nghệ, doanh nghiệp có thể tối ưu hóa hoạt động kinh doanh, tăng cường khả năng phát hiện và tận dụng cơ hội trong môi trường kinh doanh ngày càng cạnh tranh và phức tạp.
Cấu trúc quản lý dữ liệu mẫu
Bảng Cấu trúc quản lý dữ liệu mẫu
| Phân phối và tiêu thụ dữ liệu | Báo cáo quy trình hoạt động | Báo cáo quy trình quản lý và BI | Thống kê nâng cao | Ứng dụng dựa trên dữ liệu | Dữ liệu luồng |
| Đưa dữ liệu vào khô tồn | ODS | Kho dữ liệu | Kho lưu trữ trung tâm | ||
| Sử dụng dữ liệu và lấy dữ liệu từ nguồn | Phần mềm cho quy trình hoạt động | Quản lý dữ liệu tổng | |||
| Cấu trúc quản lý dữ liệu | Cấu trúc quản lý dữ liệu | ||||
Quá trình tích hợp hệ thống dữ liệu bắt đầu từ việc thu thập dữ liệu từ các nguồn khác nhau và chuyển đến hệ thống dữ liệu luồng. Dữ liệu sau đó được đưa vào kho dữ liệu tạm thời (ODS) và sau đó chuyển đến kho dữ liệu trung tâm.
Từ đây, dữ liệu được phân phối và sử dụng để tạo báo cáo quy trình hoạt động và thống kê nâng cao. Các ứng dụng dựa trên dữ liệu được phát triển để tối ưu hóa hoạt động kinh doanh và phần mềm được sử dụng để quản lý các quy trình hoạt động liên quan đến dữ liệu. Quản lý dữ liệu tổng thể đảm bảo tính toàn vẹn và sẵn sàng của dữ liệu, đồng thời bảo đảm tuân thủ các quy định pháp luật.
Một số bộ phận có hạn về khả năng quản lý sự phức tạp, nhưng vẫn duy trì các chức năng quan trọng như thống kê nâng cao và báo cáo quy trình làm việc.
Có nhiều lớp để quản lý dòng chảy dữ liệu một cách rõ ràng và tạo ra nguồn duy nhất để bảo vệ hệ thống khỏi gián đoạn và thiếu đồng nhất, thông qua việc sử dụng kho dữ liệu để tích hợp dữ liệu từ nhiều nguồn.
Việc tích hợp giải pháp mới với các bộ phận truyền thống như kho dữ liệu giúp đáp ứng các yêu cầu như xử lý dữ liệu thời gian thực và tạo ra một cơ sở dữ liệu quản lý quy trình hoạt động (ODS) mới dựa trên công nghệ tiên tiến.
Mục đích của mô hình cấu trúc trên đây giúp DN làm kỹ thuật về quản lý dữ liệu:
- Hỗ trợ khách hàng trong việc nghiên cứu và đánh giá các lựa chọn một cách có hệ thống trước khi thảo luận về các giải pháp kỹ thuật.
- So sánh các bộ phận kỹ thuật số với khả năng của công ty để tránh sự trùng lặp và xác định những thiếu sót.
- Lập kế hoạch biến đổi từng bước dựa trên giá trị kinh doanh, đồng thời giảm thiểu sự gián đoạn trong công việc.
Tóm lại, cấu trúc quản lý là cơ sở dữ liệu để doanh nghiệp nắm bắt mối liên kết giữa các phần dữ liệu khác nhau và xây dựng một hệ thống thông tin hoàn chỉnh. Điều này giúp tăng cường khả năng hiểu biết về thông tin, cung cấp cái nhìn toàn diện về hoạt động kinh doanh và hỗ trợ quyết định nhanh chóng và chính xác.
Giải pháp quản lý dữ liệu với với NAS Synology

NAS Synology là một thương hiệu chuyển đổi số giúp quản lý và bảo vệ dữ liệu cho các doanh nghiệp. NAS Synology cam kết đem lại những giải pháp quản lý dữ liệu an toàn và hiệu quả cho mọi quy mô, giúp doanh nghiệp dễ dàng tiếp cận và kiểm soát dữ liệu số ngày càng tăng một cách linh hoạt và tiện lợi.
Các lợi ích của việc sử dụng NAS Synology cho doanh nghiệp bao gồm:
- Truy cập và chia sẻ: Dễ dàng truy cập và chia sẻ dữ liệu từ mọi thiết bị và mọi nơi một cách nhanh chóng và thuận tiện.
- Tích hợp đa nền tảng: NAS Synology dễ dàng tích hợp vào bất kỳ môi trường nào, với hỗ trợ rộng rãi cho các trình duyệt, nền tảng di động, hệ điều hành và giao thức truyền mạng.
- Chia sẻ tệp và thư mục: Cung cấp khả năng chia sẻ tệp và thư mục một cách đơn giản và an toàn thông qua việc sử dụng liên kết hoặc mã QR, đồng thời cho phép định cấu hình các tùy chọn bảo mật và quyền truy cập để bảo vệ dữ liệu tốt nhất.
Kết luận
Có thể thấy, trong tổ chức và quản lý dữ liệu của một doanh nghiệp, cấu trúc dữ liệu đóng vai trò quan trọng không thể phủ nhận. Với mục đích giúp tăng tính hiệu quả, dễ dàng truy cập và xử lý thông tin, cũng như ảnh hưởng sâu rộng đến mọi khía cạnh của hoạt động kinh doanh, việc hiểu và áp dụng các kiểu cấu trúc dữ liệu thông dụng sẽ giúp doanh nghiệp phát triển và vận hành một cách hiệu quả hơn.












